Learning Dynamics, Noether and Symmetry Breaking in Neural Networks: A Deeper Dive
We're all building these things, these colossal mathematical functions we call neural networks, and they somehow learn. It’s often a messy, heuristic-driven process, relying on stochastic gradient descent to navigate landscapes with more local minima than stars in the observable universe. But what if we approach this seemingly empirical process with a more fundamental lens, one borrowed from the bedrock of theoretical physics? What insights can we glean by considering symmetries and their breaking in the context of neural network optimization?
Noether's Theorem: Conserved Quantities from Invariance
Let's begin with the classic. Noether's Theorem, a cornerstone of modern physics, beautifully posits a profound connection: for every continuous symmetry in a physical system's action, there exists a corresponding conserved quantity. Think of it: the continuous symmetry of time translation yields the conservation of energy; spatial translation implies momentum conservation; rotational invariance gives us angular momentum. It's an elegant mathematical statement about the deep relationship between a system's invariances and its fundamental invariants.
Now, how does this possibly map to a neural network, a computational graph of weighted sums and non-linearities? We're not talking about billiard balls or galaxies here. Yet, networks do possess intrinsic symmetries, and their optimization processes fundamentally involve the breaking of these very symmetries.
Inherent Symmetries in Neural Network Architectures
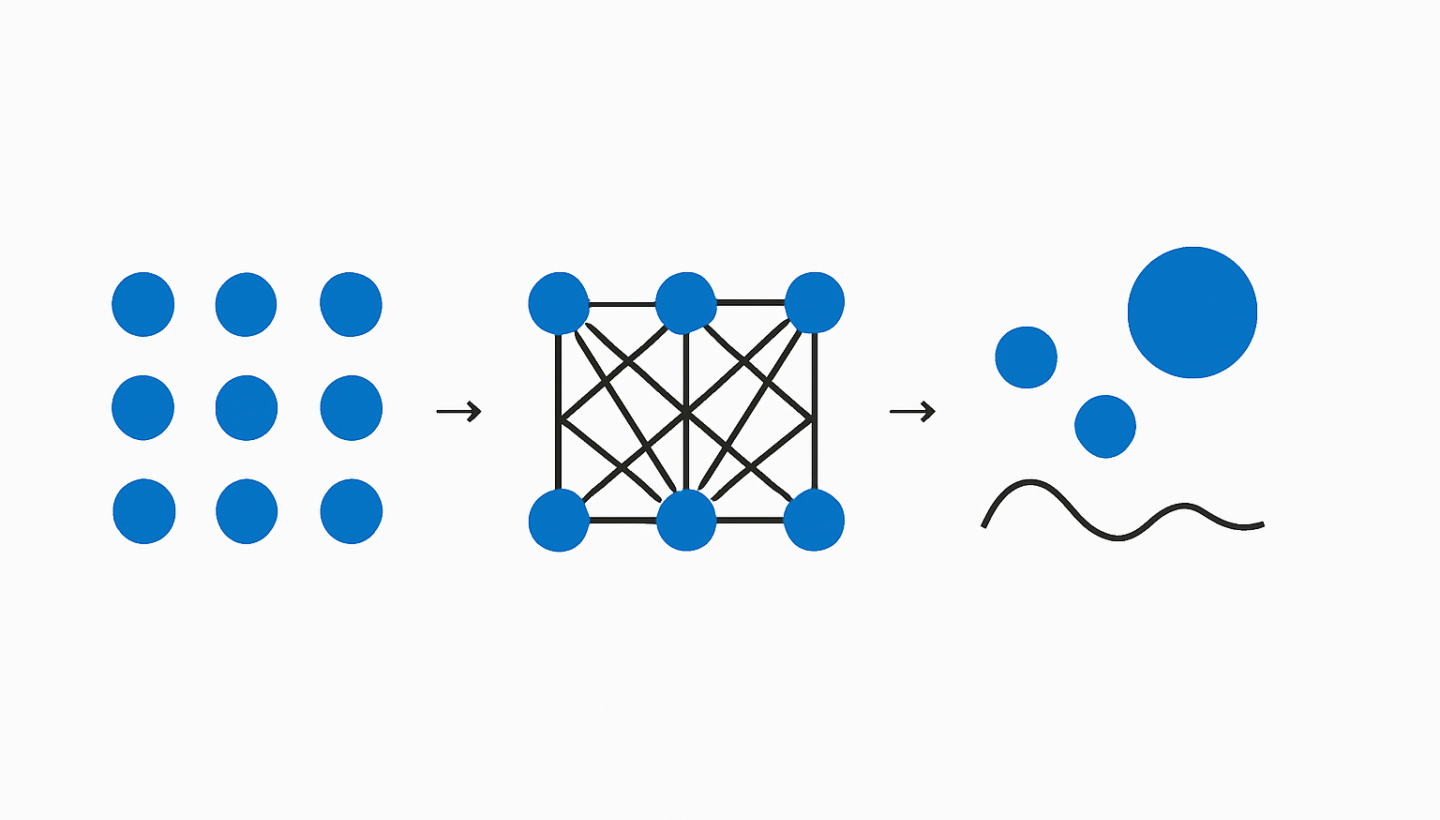
Consider a standard feedforward neural network. One of the most obvious and critical symmetries is permutation invariance within a layer. If you swap two neurons (and their associated incoming and outgoing weights) within the same hidden layer, the overall function mapping input to output remains identical. Mathematically, this means there's a vast degeneracy of equivalent solutions in the loss landscape. For a layer with N neurons, there are N! permutations that yield the exact same input-output mapping. This isn't just a curiosity; it contributes significantly to the complexity of the optimization problem.
Beyond permutation, initialization also introduces a form of symmetry. Often, weights are initialized from a zero-mean, symmetrical distribution, attempting to keep neurons initially undifferentiated and unbiased. This imparts an initial symmetry, a "balanced ignorance," across the network's processing units.
The Act of Learning: Explicit Symmetry Breaking
The fascinating part is that neural network learning, particularly via gradient descent, is an active process of symmetry breaking.
From Initialization: The moment we introduce training data and compute gradients, the initial symmetry of equivalent neurons begins to break. Small random fluctuations in initial weights, or the stochastic nature of mini-batch gradients, nudge these initially identical neurons onto diverging paths. What started as N! equivalent neurons rapidly differentiates, with each neuron specializing in detecting specific features or patterns. The loss landscape is riddled with these equivalent minima, and SGD "chooses" one particular permutation by virtue of its stochastic trajectory.
Feature Specialization: This symmetry breaking isn't arbitrary. It's driven by the data and the optimization objective. Neurons that were once interchangeable become highly specialized feature detectors. For instance, in an image classifier, one neuron might become strongly activated by edges, another by textures, and so on. This specialization is a direct consequence of the initial permutation symmetry being shattered by the learning dynamics.
Generalization and Regularization: Understanding this dynamic has practical implications. Techniques like dropout can be seen as explicitly introducing noise that breaks certain symmetries (e.g., co-adaptation of neurons), effectively forcing the network to find more robust, less symmetric solutions. Similarly, the implicit regularization properties of large learning rates in SGD can sometimes be interpreted as driving the optimizer towards "flatter" minima which often correspond to broader basins of attraction, potentially related to certain symmetries of the loss landscape.
Implications and Future Directions
Viewing neural network training through the lens of Noether's Theorem and symmetry breaking offers a powerful conceptual framework. It moves us beyond simply "optimizing a function" to understanding the underlying invariances and how the learning process systematically breaks them to achieve complex functionality.
This perspective could inspire new research avenues:
Developing symmetry-aware architectures that explicitly exploit or enforce certain invariances for improved efficiency or generalization.
Designing optimization algorithms that better manage or leverage inherent symmetries for faster convergence or avoidance of degenerate minima.
A deeper theoretical understanding of generalization could emerge from analyzing which symmetries are preserved or broken during learning, and how this relates to a model's robustness and capacity to transfer knowledge.
It's a field where the elegant principles of physics might just illuminate the opaque, often counter-intuitive world of artificial intelligence. And frankly, that's a vibe I can definitely get behind.
Publicerat av: